随着数据规模的爆炸式增长,大数据系统的数据采集与处理存储支持已成为现代企业数字化转型的核心。数据采集产品作为大数据系统的入口,其架构设计与数据处理存储服务的高效协同直接影响整体系统的性能与可靠性。本文将从数据采集产品架构的组成要素出发,并深入探讨其与数据处理和存储支持服务的集成机制。
一、数据采集产品的架构分析
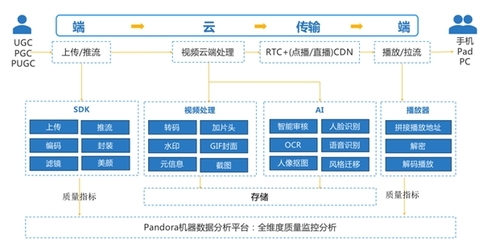
数据采集产品通常采用分层架构设计,以支持高并发、低延迟和可扩展的数据接入。其核心组件包括:
- 数据源适配层:负责对接多样化数据源,如日志文件、数据库、物联网设备、API接口等,通过连接器或代理程序实现数据抽取。
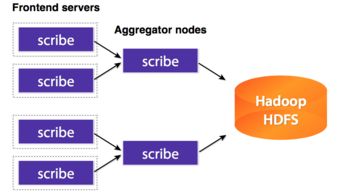
- 数据传输层:采用消息队列(如Kafka、RabbitMQ)或流处理引擎(如Flink、Spark Streaming)进行数据缓冲与实时流转,确保数据不丢失且有序传输。
- 数据预处理层:在数据进入存储前进行清洗、过滤、格式转换和轻量聚合,以降低后续处理负载。
- 控制与管理层:提供配置管理、监控告警、调度协调等功能,保障采集流程的可运维性。
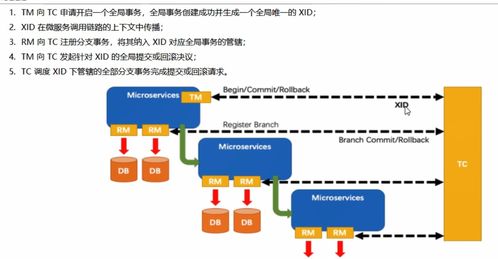
典型架构示例中,分布式部署是主流趋势。例如,采用微服务架构将各层模块解耦,结合容器化技术实现弹性伸缩,并通过统一元数据管理维护数据血缘关系。
二、数据处理与存储支持服务的关键作用
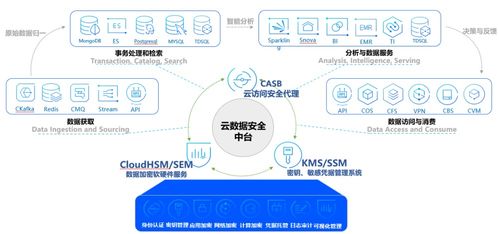
数据处理和存储服务为采集到的数据提供价值挖掘与持久化能力,其核心支撑体现在:
- 数据处理流水线:通过批处理(如MapReduce、Spark)与流处理(如Storm、Flink)引擎,实现数据的实时分析与离线计算。例如,流处理可对采集的传感器数据进行即时异常检测,而批处理支持历史数据的深度聚合分析。
- 分布式存储体系:采用多级存储策略,包括:
- 热数据存储:使用内存数据库(如Redis)或列式存储(如HBase)支持低延迟查询。
- 温数据存储:依托分布式文件系统(如HDFS)或对象存储(如S3)平衡性能与成本。
- 冷数据存储:通过归档至低成本介质(如磁带库)实现长期留存。
- 数据治理与安全:集成元数据管理、数据质量监控与加密访问控制,确保数据在生命周期内的合规性与一致性。
三、架构协同优化实践
在实际系统中,数据采集产品需与处理存储服务深度耦合。例如:
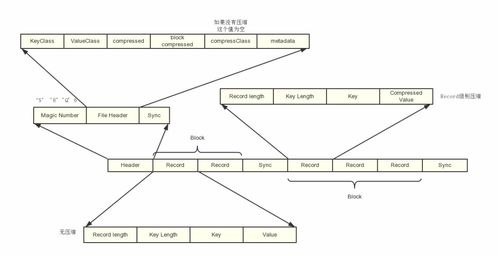
- 通过Schema-on-Read技术(如Parquet格式),采集层可直接将数据写入存储系统,由处理层按需解析,提升灵活性。
- 利用存储计算分离架构,采集数据持久化至云原生存储(如Delta Lake),处理服务按负载动态调配资源,实现成本优化。
- 引入数据湖仓一体模式,统一采集入口,支持原始数据直接入湖(Data Lake),并经ETL管道转换后入仓(Data Warehouse),满足多场景分析需求。
大数据采集产品的架构演进正朝着智能化、云原生与实时化方向发展。其与数据处理存储服务的无缝集成,不仅提升了数据流转效率,更通过弹性扩展与智能治理,为业务创新提供了坚实基础。未来,随着边缘计算与AI技术的融合,采集与处理存储的边界将进一步模糊,形成更敏捷的数据驱动体系。