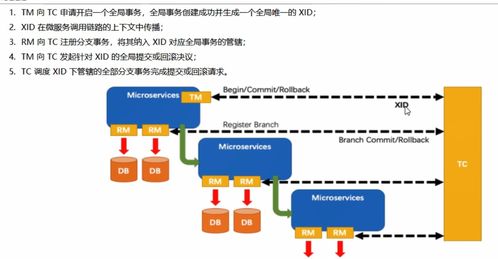
Seata 是由阿里巴巴开源的分布式事务解决方案,致力于提供高性能和易用性的分布式事务服务。它通过 AT(自动补偿型事务)、TCC(Try-Confirm-Cancel)、SAGA 和 XA 等模式,支持跨多个微服务的数据一致性。以下将详细介绍 Seata 的配置过程、常见使用场景,以及其对数据处理和存储服务的支持。
一、Seata 配置
Seata 的配置主要包括服务端和客户端两部分:
- 服务端配置:
- 下载 Seata Server 发行版并解压。
- 配置存储模式:支持文件、数据库(如 MySQL、PostgreSQL)或 Redis,例如在 file.conf 中设置 store.mode = "db",并配置数据库连接信息。
- 配置注册中心:Seata Server 需要注册到注册中心(如 Nacos、Eureka、Zookeeper),在 registry.conf 中指定注册中心类型和地址。
- 启动 Seata Server,通常通过运行 seata-server.sh(Linux)或 seata-server.bat(Windows)完成。
- 客户端配置:
- 在微服务项目中引入 Seata 依赖,例如对于 Java 项目,使用 Spring Cloud Alibaba Seata 组件。
- 配置 application.yml 或 application.properties:指定事务组名称(如 tx-service-group: "mytxgroup")、注册中心地址和 Seata Server 服务地址。
- 在业务方法上添加 @GlobalTransactional 注解,以启用分布式事务管理。
二、Seata 使用场景
Seata 适用于多种分布式事务场景,尤其是微服务架构中需要跨服务数据一致性的情况:
- 电商订单处理:当用户下单时,涉及库存服务、订单服务和支付服务,Seata 可确保这些操作要么全部成功,要么全部回滚。
- 银行转账:跨账户的转账操作需要保证原子性,Seata 通过事务协调防止数据不一致。
- 数据一致性要求高的系统:如库存管理、财务系统等,其中部分失败可能导致业务逻辑错误,Seata 提供可靠的事务保障。
- 多云或混合云环境:Seata 支持跨不同数据源和服务,适用于复杂部署场景。
三、数据处理和存储支持服务
Seata 在数据处理和存储方面提供了灵活的支持:
- 数据存储:Seata Server 支持多种存储模式来持久化事务日志和状态:
- 文件存储:适用于测试或小规模环境,配置简单但性能有限。
- 数据库存储:推荐用于生产环境,支持 MySQL、Oracle、PostgreSQL 等,通过数据库事务确保数据一致性。
- Redis 存储:适用于高并发场景,提供快速读写能力。
- 数据处理:Seata 通过 undolog 表记录数据修改前的快照,在事务回滚时自动恢复数据。客户端需在业务数据库中创建 undolog 表,并确保数据操作的幂等性。
- 支持服务集成:Seata 可与常见数据处理框架(如 Spring Boot、Dubbo)和存储服务(如 MySQL、Redis)无缝集成,通过配置即可实现分布式事务管理。
Seata 是一个强大的分布式事务工具,通过简单配置即可在微服务环境中确保数据一致性。其灵活的使用场景和对多种存储模式的支持,使其成为处理分布式事务的理想选择。在实际应用中,建议根据业务需求选择合适的模式和存储方案,并进行充分测试以优化性能。