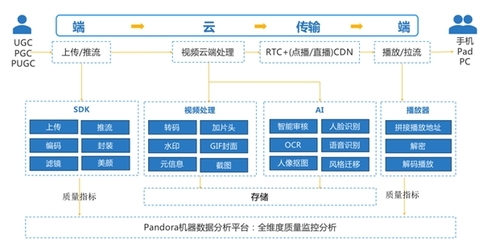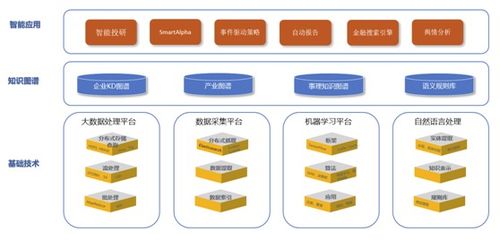
在现代数据分析领域,高效的数据存储和处理是确保洞察力和业务决策准确性的关键。本文将介绍数据分析中常见的存储方式以及支持数据处理和存储的相关服务。
一、数据分析中常见的存储方式
1. 关系型数据库
关系型数据库使用表格结构存储数据,以行和列的形式组织信息。常见的例子包括MySQL、PostgreSQL和Oracle。它们适用于结构化数据,支持SQL查询,确保数据的一致性和完整性,但可能在处理大规模非结构化数据时效率较低。
2. 非关系型数据库(NoSQL)
NoSQL数据库设计用于处理非结构化或半结构化数据,常见类型包括文档数据库(如MongoDB)、键值存储(如Redis)、列存储(如Cassandra)和图数据库(如Neo4j)。它们具有高可扩展性和灵活性,适合大数据和实时应用场景。
3. 数据仓库
数据仓库是专门为分析和报告设计的大型存储系统,如Amazon Redshift、Google BigQuery和Snowflake。它们优化了复杂查询,支持历史数据分析,通常集成来自多个源的数据,适合企业级商业智能应用。
4. 数据湖
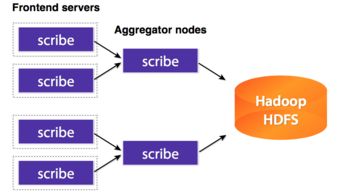
数据湖是一个集中式存储库,可以存储任意规模的结构化、半结构化和非结构化数据,例如使用Hadoop HDFS或云服务如AWS S3。它支持原始数据存储,便于后续处理和分析,但需要有效的数据治理来避免成为“数据沼泽”。
5. 分布式文件系统
分布式文件系统,如HDFS(Hadoop Distributed File System),设计用于在多个节点上存储和处理大量数据。它适合大数据框架如Apache Spark和Hive,提供高容错性和可扩展性。
二、数据处理和存储支持服务
为了高效管理数据存储和处理,许多支持服务应运而生,主要包括:
1. 云存储服务
云提供商如AWS、Google Cloud和Microsoft Azure提供可扩展的存储解决方案,如S3、Google Cloud Storage和Azure Blob Storage。这些服务提供高可用性、安全性和成本效益,支持按需扩展。
2. 数据处理框架
框架如Apache Spark、Apache Flink和Apache Hadoop支持大规模数据处理,包括批处理和流处理。它们可以与多种存储系统集成,加速数据转换和分析过程。
3. 数据集成与ETL工具
ETL(提取、转换、加载)工具,如Talend、Informatica和Apache NiFi,帮助从不同源提取数据,进行清洗和转换,然后加载到目标存储系统中。这些服务简化了数据流水线管理。
4. 数据治理与安全服务
服务如Collibra和AWS Lake Formation提供数据治理、元数据管理和安全策略,确保数据质量、合规性和访问控制,这对于维护数据湖和仓库的可靠性至关重要。
5. 监控与优化工具
工具如Prometheus、Grafana和云原生监控服务(如AWS CloudWatch)帮助跟踪存储和处理的性能,优化资源使用,并及时发现故障。
数据分析的成功依赖于选择合适的存储方式和支持服务。关系型数据库、NoSQL、数据仓库、数据湖和分布式文件系统各具优势,而云服务、处理框架、ETL工具、治理方案和监控工具则提供了全面的支持。企业在实际应用中应根据数据类型、规模和分析需求进行组合使用,以实现高效、可靠的数据分析流程。